
Can we use frequency analysis to increase our odds of winning something in the game of TOTO (P.S. ChatGPT helped me)
It was a day before the eve of Chinese New Year 2023 and everyone around me was excitedly speaking about the Toto draw that was happening that evening. Most of us, though we know it’s a game of chance, were indeed hoping for a surprise.
This made me wonder, can someone use simple frequency analysis to increase the odds of winning ?
SOME OF THE ASSUMPTIONS I MAKE HERE MIGHT BE WRONG AND THIS ANALYSIS IS PURELY FOR EDUCATIONAL PURPOSES. BETTING IS A GAME OF RANDOM CHANCE. PLEASE ACT WISELY.
If you’re not familiar with toto, you can check this link to learn more https://online.singaporepools.com/en/lottery/how-play-toto
In order to win something (at least $10), you need at least 3 numbers out of the 6 winning numbers to appear in the results. Details on prize group breakdown is listed at this link
https://online.singaporepools.com/en/lottery/toto-prize-structure
So my thought was, can i just pick sets of numbers that tend to historically either
- Appear more frequently ?
- Appear together more ?
For this, i required historical results.
1. Download data in CSV format
Initially I thought I had to scrape this data, but thankfully, this website gave the data beautifully in CSV format. It dates back all the way to 2008 with 1495 results (as of 20 Jan 2023).
https://en.lottolyzer.com/utility/singapore/toto
This is just what the Pandas library required for me to kick start my analysis.
2. Create Python Virtual Environment
I’m using a Mac M1Pro and I’ve installed the required libraries. Conda and pip are the package managers i’m using to create my environment. Created an environment called toto with python version 3.9 as such
conda create -n toto python=3.9conda activate toto3. Install Libraries
You can install the required libraries by using pip
pip install pandas seaborn4. Write frequency analysis function
I wanted to write a simple frequency analysis function. But being lazy, I got ChatGPT to help me. This is what ChatGPT created with a simple prompt.
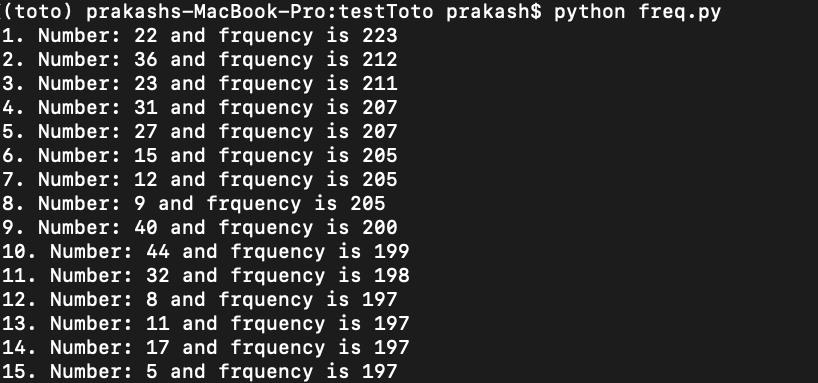
I made small tweaks to get better results and it saved a lot of time compared to writing this from scratch. Thus, the first 15 numbers with the highest frequency were (in descending order)
The full code is as such
import pandas as pd
def frequency_sort(lists):
# Create an empty dictionary to store the frequency of each number
frequency = {}
for sublist in lists:
for num in sublist:
if num in frequency:
frequency[num] += 1
else:
frequency[num] = 1
# Sort the dictionary by frequency in descending order
sorted_frequency = dict(sorted(frequency.items(), key=lambda x: x[1], reverse=True))
return (sorted_frequency)
df = pd.read_csv('ToTo.csv')
new_set = df[['Winning Number 1', '2', '3', '4', '5', '6']]
new_list = new_set.values.tolist()
res = frequency_sort(new_list)
counter=0
for i in res:
print(f"{counter+1}. Number: {i} and frquency is {res[i]}")
counter+=1
if counter == 15:
break
5. Pick 6 Numbers
I picked the 6 numbers from the 15 most frequent numbers using the tool from this link. It allows the numbers to be distributed well in all combinations.
https://en.lottolyzer.com/utility/singapore/toto
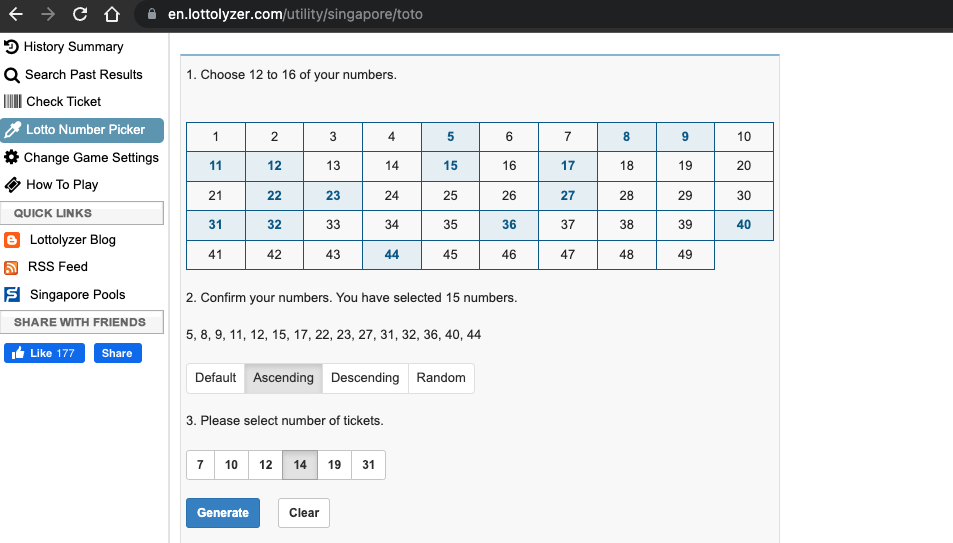
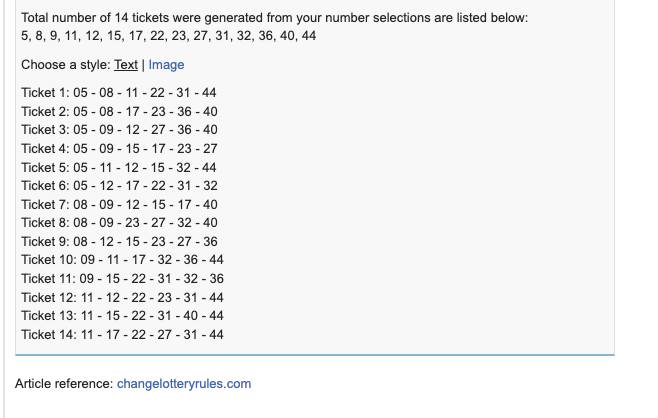
The 14 possible numbers generated was
6. Write a BackTest
Picking different combinations of 6 numbers from the first 15 numbers that have the highest frequencies could allow us to have a better chance. In order to test this, writing a backtest would be necessary.
A backtest will allow us to see if this strategy of picking frequent numbers would work well with historical data.
I'm only using the 6 numbers to simply the calculations, thus only Group 7 ($10), Group 5 ($50), Group 3 (think 5.5% of pool prize) and Group 1 can be calculated.
The backtest code is as such
import pandas as pd
df = pd.read_csv('ToTo.csv')
num_of_tickets = 14
price_per_ticket = 1
possible_numbers = [
[5, 8, 11, 22, 31, 44],
[5, 8, 17, 23, 36, 40],
[5, 9, 12, 27, 36, 40],
[5, 9, 15, 17, 23, 27],
[5, 11, 12, 15, 32, 44],
[5, 12, 17, 22, 31, 32],
[8, 9, 12, 15, 17, 40],
[8, 9, 23, 27, 32, 40],
[8, 12, 15, 23, 27, 36],
[9, 11, 17, 32, 36, 44],
[9, 15, 22, 31, 32, 36],
[11, 12, 22, 23, 31, 44],
[11, 15, 22, 31, 40, 44],
[11, 17, 22, 23, 31, 44]
]
new_set = df[['Winning Number 1', '2', '3', '4', '5', '6']]
new_list = new_set.values.tolist()
print(new_list)
finale = {"G7":0, "G5":0, "G3":0, "G1":0, "Lose":0}
for result in new_list:
for seta in possible_numbers:
matches = 0
for num in seta:
if num in result:
matches+=1
if matches == 3:
finale["G7"] +=1
elif matches == 4:
finale["G5"] +=1
elif matches == 5:
finale["G3"] +=1
elif matches == 6:
finale["G1"] +=1
else:
finale["Lose"] +=1
print(finale)
7. Results
G7 is group 7, G5 is group 5, G3 is group 3 and G1 is group 1. If less than 3 numbers appear, we lose.
The results showed as such

There were 1495 results and we bet 14 numbers on every occasion, a total of 1495*14.
We lost 20352 times or $20352 since 2008, but won 555*$10 + 19 * $50 and 4 * 5.5% of the prize pool money.
I’ll leave the conclusions to my readers and again, this is for educational purposes only. I do not bet either as its a game of random chance, but I hope this analysis gives a starter.
In the next post, i’ll address statistics of picking numbers that occur frequently together.




